Welcome to SNNGrow’s documentation!
English | 简体中文
SNNGrow is a low-power, large-scale spiking neural network training and inference framework. SNNGrow does not rely on specialized hardware to implement an energy-efficient spiking computation mode. Using Cutlass, SNNGrow develops fundamental operations for spiking data (such as GEMM), replacing high-power-consuming multiply-add(MAD) operations with low-power addition(ADD) operations. Additionally, SNNGrow further reduces storage and bandwidth costs by utilizing the binary nature of spikes, resulting in several times speedup and storage savings. It preserves minimal energy cosumption while providing the superior learning abilities of large spiking neural network.
The vision of SNNGrow is to decode human intelligence and the mechanisms of its evolution, and to provide support for the development of brain-inspired intelligent agents in a future society where humans coexist with artificial intelligence.
SNNGrow supports low-power sparse computation. It defines a SpikeTensor data structure for spike data. Thanks to the binarization property of spike, this data structure uses low bit storage at the underlying level, and only needs 1Byte to store the spike data. Meanwhile, for SpikeTensor, SNNGrow uses CUDA and CUTLASS to customize low-energy operators, such as matrix multiplication for SpikeTensor, to really replace multiplication with addition from the bottom layer.
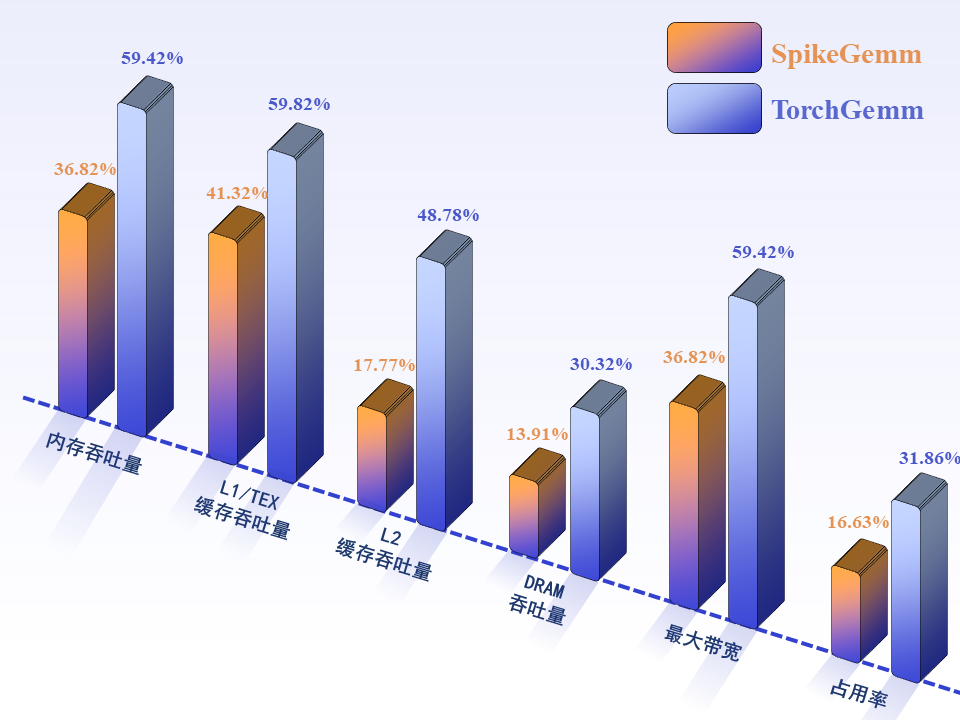
Visualizing the matrix multiplication instruction call of spike matrix multiplication and torch on GPU, in SNNGrow, compared with torch, the matrix multiplication is realized by completely using addition operation, which will save a lot of energy consumption and reduce the storage requirements.

SNNGrow will bring several times the speed up. We measured the speed of matrix multiplication. Compared to the same scale torch matrix multiplication, SNNGrow can bring more than 2 times the speed up.

Benefiting from the data form of pulses, SNNGrow only requires less memory footprint and bandwidth requirements, which means that SNNGrow can run larger models with the same hardware resources.
Snngrow provides STDP(Spike Timing Dependent Plasticity) learning rule, which can be used to learn the weights of fully connected layers.

Snngrow provides connection mode of sparse synapses, which can be used to build sparse structures.
USAGE: