教程
神经元
在SNNGrow中,脉冲神经元是脉冲神经网络的基本单元。不同于深度学习中常见的神经元,脉冲神经元具有生物仿生的神经动力学,并且使用离散的脉冲值作为输出。脉冲神经元的输出是离散的,通常为0或1。在SNNGrow中,神经元的数量是在初始化或调用 reset() 函数重新初始化后,根据第一次接收的输入的 shape 自动决定的。重置神经元状态的代码可以在 snngrow.base.utils() 中找到:
def reset(net: nn.Module):
for m in net.modules():
if hasattr(m, 'reset'):
if not isinstance(m, BaseNode.BaseNode):
logging.warning(f'Trying to call `reset()` of {m}, which is not snngrow.base.neuron'
f'.BaseNode')
m.reset()
得益于神经元动力学,脉冲神经元是有状态的,也可以说具有记忆。通常,脉冲神经元的膜电位作为其状态变量。在喂入下一个样本之前,需要调用 reset() 函数清除脉冲神经元的先前状态。SNNGrow神经元都继承自 snngrow.base.neuron.BaseNode() ,共享相同的fire和reset方程。任何离散的脉冲神经元都可以用三个离散方程描述(神经动力学,激发,重置)。神经动力学和重置的方程如下。
@abstractmethod
def neuronal_dynamics(self, x: torch.Tensor):
"""
The neuronal dynamics difference equation. The sub-class must implement this function.
"""
raise NotImplementedError
def neuronal_fire(self, x: torch.Tensor):
"""
The neuronal fire difference equation.
"""
if self.training:
return self.surrogate_function(self.v - self.v_threshold)
else:
return (self.v >= self.v_threshold).to(x)
其中 \(X[t]\) 是输入,如外部输入电流; \(V[t]\) 是输出脉冲后的神经元膜电位; \(f(V[t-1],X[t])\) 是神经元状态的神经动力学方程。不同类型的神经元的神经动力学方程是不同的; \(\Theta(x)\) 是激活函数。在这个框架中,广泛使用的一个函数是阶跃(Heaviside)函数。在前向传播过程中,如果输入大于或等于阈值,则返回1;否则返回0。这样的 tensor 只有0或1元素被视为脉冲。阶跃函数的方程如下:
输出脉冲会消耗先前由脉冲神经元积累的电荷,导致膜电位的瞬时降低,即膜电位的重置。在SNNGrow中,膜电位有两种重置方式:
硬重置模式,在输出脉冲后,膜电位直接重置到重置电压:
def hard_reset(v: torch.Tensor, spike: torch.Tensor, v_reset: float):
v = (1. - spike) * v + spike * v_reset
return v
软重置模式,在输出脉冲后,膜电位与阈值电压的差值作为重置电压:
def soft_reset(v: torch.Tensor, spike: torch.Tensor, v_threshold: float):
v = v - spike * v_threshold
return v
软重置的神经元不需要重置电压 \(V_{reset}\) 变量。在 snngrow.base.neuron.BaseNode() 的神经元中,其中一个构造函数参数 \(V_{reset}\) ,默认为1.0,表示神经元可以使用硬重置;如果设置为None,则使用软模式重置。
替代梯度
在SNNGrow中,前向传播使用阶跃函数。但是阶跃函数是不连续的,其导数是Dirichlet函数(冲击函数),其方程是:
Dirichlet函数在0处为 \(+\infty\) 。如果直接使用Dirichlet函数进行梯度下降,将使网络的训练极其不稳定。因此,在反向传播期间使用替代梯度 [1]。
替代梯度方法的原理是,在前向传播期间使用 \(\Theta(x)\) ,而在反向传播期间使用 \(\frac{\mathrm{d} y}{\mathrm{d} x} =\sigma ^{'} (x)\) ,其中 \(\sigma (x)\) 是替代函数。 \(\sigma (x)\) 通常是与 \(\Theta(x)\) 形状相似的函数,但是光滑和连续的。替代函数在神经元中用于生成脉冲的近似梯度。
在SNNGrow中,替代梯度函数在基类中实现,提供了一些常用函数的替代。替代函数可以作为参数指定给神经元构造函数, surrogate_function 。
脉冲计算模式
脉冲计算模式是SNNGrow实现低能耗的核心。在脉冲计算模式下,脉冲神经元的输出是脉冲化的,使用自定义的SpikeTensor对神经元的输出进行封装。SpikeTensor是一个包含脉冲神经元输出的张量,其继承于Pytorch的Tensor,但底层使用低精度(1 Byte)数据类型存储,其中1表示脉冲,0表示没有脉冲。在脉冲计算模式下,SNNGrow使用Cutlass针对SpikeTensor开发混合数据类型的基本运算操作(如GEMM),将高功耗的乘加运算替换成低功耗的加法运算。
脉冲计算模式无需显式的开启,只需在构建神经元时指定``spike_out`` 参数即可。
例如定义一个简单的LIF神经元:
surrogate = Sigmoid.Sigmoid(spike_out=True)
# input is a Tensor, output is a SpikeTensor
LIFNode(T=T, spike_out=True, surrogate_function=surrogate)
此时脉冲神经元的输出是一个SpikeTensor。在前向传播过程中,SpikeTensor会自动传播到下一层神经元,从而实现脉冲神经网络的训练和运行。针对SpikeTensor,SNNGrow实现了一系列上层算子,见 snngrow.base.nn 。
例如构建一个脉冲神经网络的全连接层:
import snngrow.base.nn as snngrow_nn
# input is a SpikeTensor, output is a Tensor
snngrow_nn.Linear(512, 512, spike_in=True)
更多优化算子仍在开发中,敬请期待。
STDP学习
Snngrow中提供了STDP(Spike Timing Dependent Plasticity)学习规则,可以用于全连接层的权重学习。
STDP可以使用如下公式进行描述:
其中 \(s[i][t]\) 和 \(s[j][t]\) 是突触前神经元i和突触后神经元j在t时刻发放的脉冲(0或1),迹 \(tr_{pre}[i][t]\) 和 \(tr_{post}[j][t]\) 记录突触前神经元i和突触后神经元j在t时刻的脉冲发放, \(\tau_{post}\) 和 \(\tau_{post}\) 是pre和post迹的时间常数, \(F_{pre}\) 和 \(F_{post}\) 是控制突触权重变化量的函数。
Snngrow直接对权重进行更新来实现STDP,不需要进行反向传播,也不需要额外的优化器。
使用 snngrow.base.learning.STDP() 构建一个STDP学习的全连接脉冲神经网络:
import torch
import torch.nn as nn
import snngrow.base.nn as tnn
from snngrow.base.neuron.IFNode import IFNode
from snngrow.base.surrogate import Sigmoid
from snngrow.base import utils
from snngrow.base.learning import *
from matplotlib import pyplot as plt
class STDP_SNN(nn.Module):
def __init__(self,):
super().__init__()
self.node = []
self.connection = []
self.node.append(IFNode(parallel_optim=False, T=T, spike_out=False, surrogate_function=Sigmoid.Sigmoid(spike_out=False), v_threshold=1.0))
self.connection.append(tnn.Linear(4, 3, spike_in=False, bias=False))
self.stdp = []
self.stdp.append(STDP(self.node[0], self.connection[0]))
def forward(self, x):
"""
Calculate the forward propagation process and the training process.
"""
output, dw = self.stdp[0](x)
return output, dw
def updateweight(self, i, dw, delta):
"""
:param i: the index of the connection to update
:type: float
:param dw: updated weights
:type x: torch.Tensor
Update the weight of the ith group connection according to the input dw value.
"""
self.connection[i].update(dw*delta)
def reset(self):
"""
Reset neurons or intermediate quantities of learning rules.
"""
for i in range(len(self.node)):
self.node[i].reset()
for i in range(len(self.stdp)):
self.stdp[i].reset()
生成输入脉冲,初始化网络的权重为0.4,在T个时间步内进行STDP的学习,记录脉冲、迹和权值的变化:
N_in, N_out = 4, 3
T = 100
batch_size = 2
lr = 0.01
in_spike = (torch.rand([T, batch_size, N_in]) > 0.7).float()
out_spike = []
trace_pre = []
trace_post = []
weight = []
stdp_snn = STDP_SNN()
nn.init.constant_(stdp_snn.connection[0].weight.data, 0.4)
for t in range(T):
output, dw = stdp_snn(in_spike[t])
out_spike.append(output)
trace_pre.append(stdp_snn.stdp[0].trace_pre)
trace_post.append(stdp_snn.stdp[0].trace_post)
stdp_snn.updateweight(0,dw*lr,1)
weight.append(stdp_snn.connection[0].weight.data.clone())
out_spike = torch.stack(out_spike) # [T, batch_size, N_out]
trace_pre = torch.stack(trace_pre) # [T, batch_size, N_in]
trace_post = torch.stack(trace_post) # [T, batch_size, N_out]
weight = torch.stack(weight) # [T, N_out, N_in]
对网络中第0个突触连接的动态进行可视化:
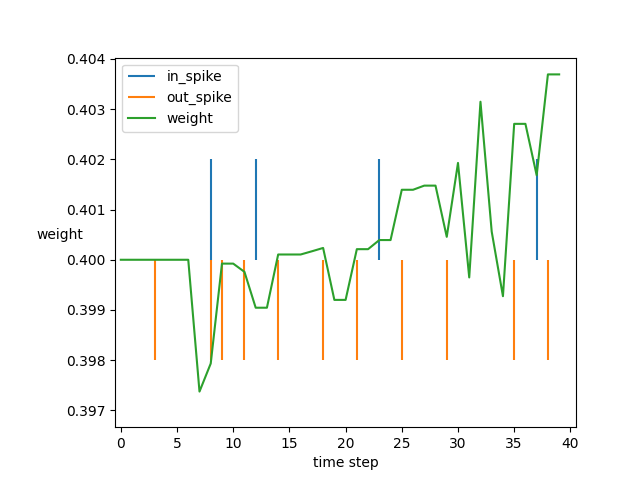
完整的代码位于 snngrow/examples/test_stdp.py。
稀疏结构
Snngrow中提供了稀疏突触的连接方式,可以用于构建稀疏结构。
使用 snngrow.base.nn.modules.sparse_synapse() 构建一个稀疏结构的脉冲神经网络:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import os
import sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
from snngrow.base.neuron.LIFNode import LIFNode
from snngrow.base import utils
from snngrow.base.nn.modules import SparseSynapse
from tqdm import tqdm
# Define the CSNN model
class CNN(nn.Module):
def __init__(self, T):
super(CNN, self).__init__()
self.T = T
self.csnn = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3),
LIFNode(parallel_optim=False, T=T, spike_out=False),
nn.MaxPool2d(kernel_size=1),
nn.Conv2d(32, 64, kernel_size=3),
LIFNode(parallel_optim=False, T=T, spike_out=False),
nn.Flatten(),
SparseSynapse(36864, 128, connection="random"),
SparseSynapse(128, 10, connection="random"),
)
def forward(self, x):
# # don't use parallel acceleration
x_seq = []
for _ in range(self.T):
x_seq.append(self.csnn(x))
out = torch.stack(x_seq).mean(0)
return out
完整的代码位于 snngrow/examples/test_sparse_synapse.py。